PGCODE update: the execution part

The last blogpost about PGCODE was the only project introduction and description.
Since then, I've added the most critical and crucial part of any SQL editor - the execution itself.
This blog post will be just a report on progress and work done in the execution part.
Editor workflow
Traditionally - all SQL tools, that I know of - have adopted the following workflow:
When a user runs an execute command (trough GUI or by keyboard) then:
- If the editor contains a selection - only the selected code will be executed.
- If the editor does not contain a selection - the entire editor content will be executed.
I have a couple of issues with this approach.
Firstly, it is a bit inconsistent. Depending on your editor state, different portions of the code will be executed.
Secondly, you may run something unintentionally. In wast majority of cases, I'd say 90% - I'm executing only selected code.
Very rarely I run entire editor content. Sometimes I forget to mark the selection for the execution and run entire editor content unintentionally which may have serious consequences.
So, to make clear what you will be executing, PGCODE has line numbers for the selected code:
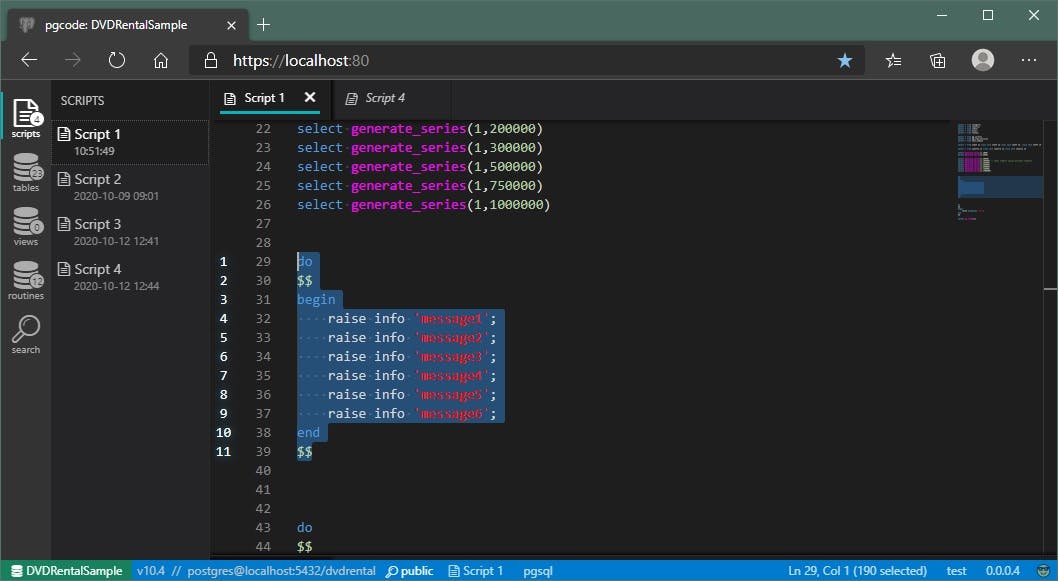
As you change your selection so will those selection line numbers change dynamically.
This will help to make clear what is about to be executed and also help later with potential error line numbers.
I think it is neat, I like it.
When there is no selection, there is no selection line number - only a PostgreSQL icon that indicates the current line being edited:
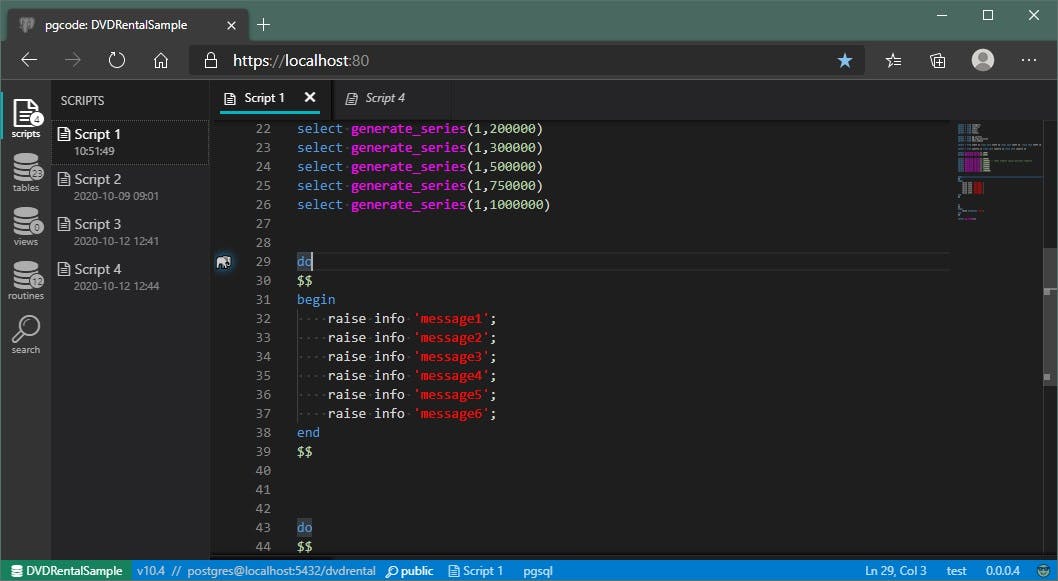
Sort of active line tracker. Cute. However, when you initiate execution with the editor in this state, you'll get this instead:
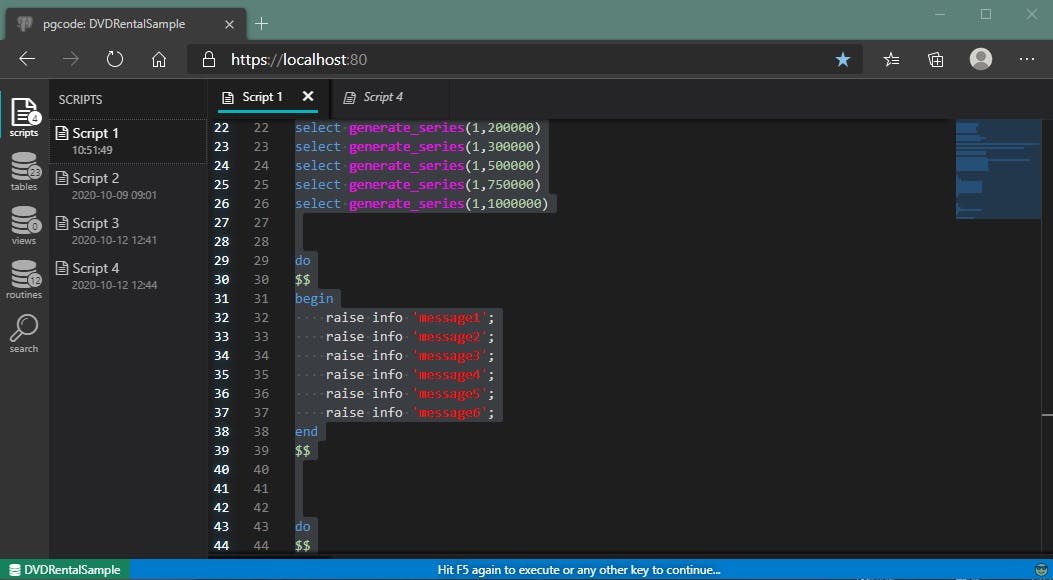
Basically, the entire content will be automatically selected and the application will go into the state where it waits for your confirmation.
That information is clearly indicated in the application footer that always reflects the current application state. I'll highlight this state visually even more, but it works for now.
So you can either hit the execution key again (F5) to execute and press any other key on the mouse or keyboard to restore the previous state of the editor, exactly where you left off.
This is, sort of, protection from unintentional executions. Hey, it can happen.
The execution initiation action itself is currently only available with editor keystroke (F5) and in the context menu:
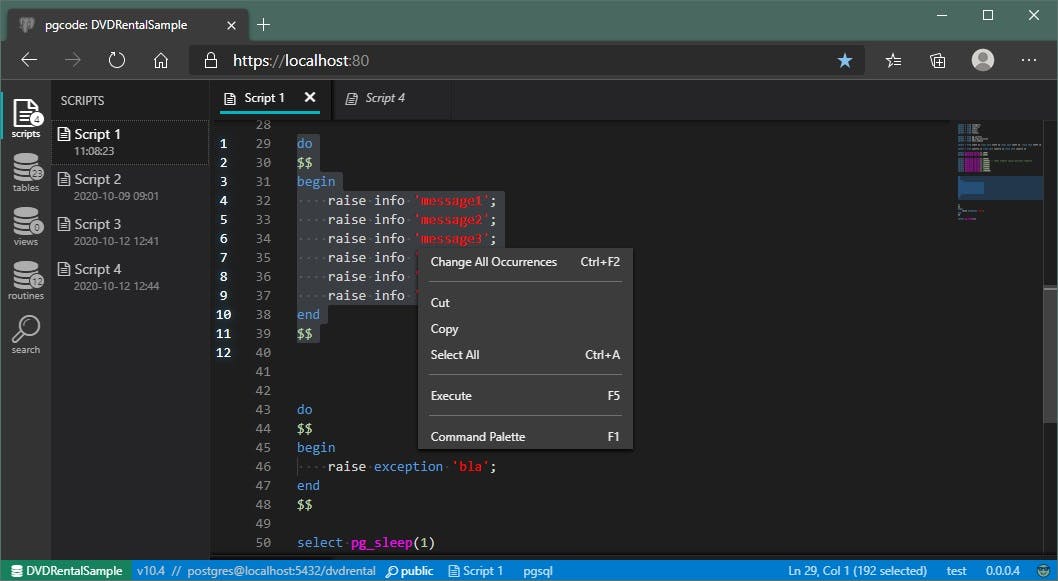
Currently, there are no other ways to initiate this command, because I can't decide what would the best way to provide this functionality (besides keystroke and a context menu).
The best idea I could think of is a toolbar at the top of the editor with start and stop buttons (and perhaps analyze in the future), but, the toolbar with only two or three buttons seems a bit suboptimal.
If anyone has a better idea, please, I'd like to hear about it, but for now, a toolbar is the only idea I have.
Results pane
Results pane is initially hidden (with minimized height to footer), but you can pull it up with the mouse, by dragging just above the footer:
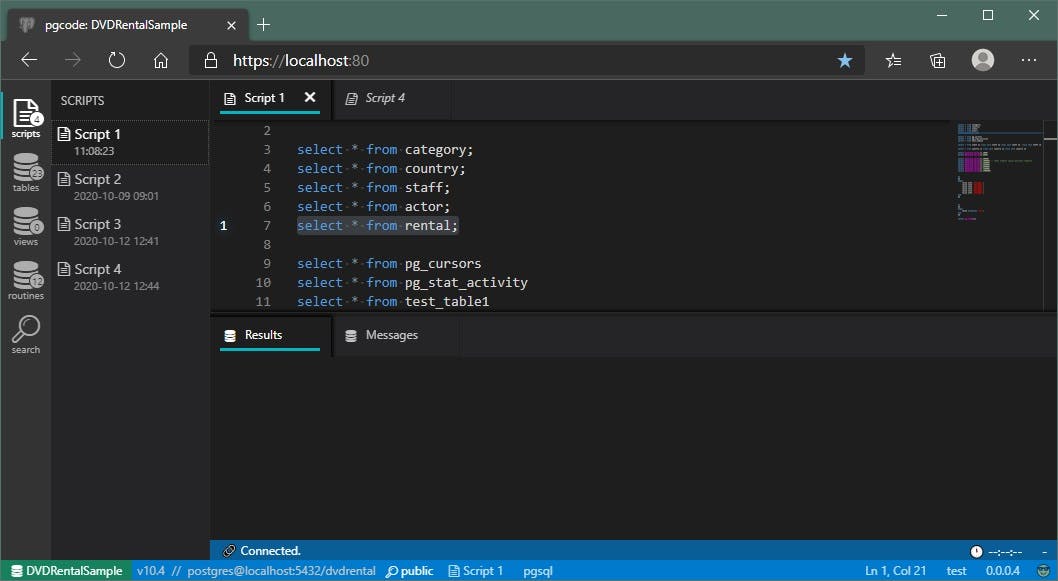
Naturally, this will happen automatically as soon as you start the execution, it will just reset to the default height to make your execution results visible.
Each editor tab has its own results pane, that can be resized individually for each tab, and, just like everything else in the application, the position is remembered, so it will remain the same as you left it.
This how it looks like after successful execution:
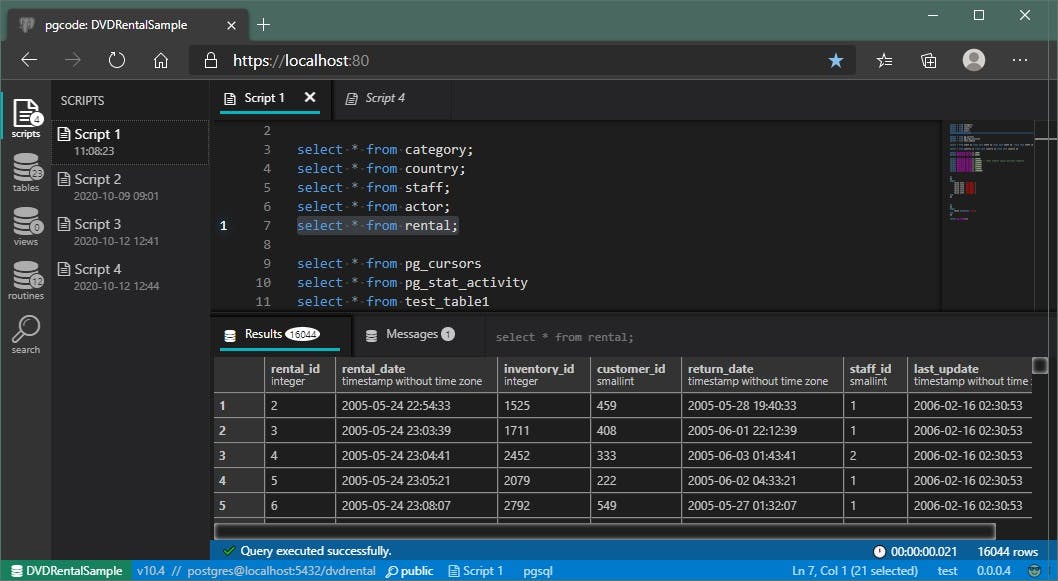
Pretty much as it is standardized and expected: results are divided into two tabs: results tab (containing the data grid) and messages (containing, well, the messages and the other useful metadata).
Each tab has a badge next to the tab title, containing the total number of items within a respective tab. In the example above 16044 results in the data grid and one message in the messages tab.
Next to those tab buttons is an actual query text itself to indicate to what query those results are referring to precisely. When working with multiple scripts and switching between multiple tabs, each having its own results pane, sometimes can be a bit confusing to know what those results are referring to. That query text is slightly dimmed no to stand out too much and trimmed to fit the area. In the future, features like a re-run query and select in the editor will be added to that query context menu. For now, this is more than enough.
As far as the data grid goes, features that are implemented are basic and so far they are:
- Smooth scrolling on any number of items.
- Column resizing.
- Mouse scroll wheel.
Obviously, things like keyboard navigation, cell selection, a context menu with export items are still to be added, but these basic functionalities and smooth scrolling being the most important - are more than enough for a start.
Smooth scrolling works great, better than similar software such as pgAdmin or Azure Data Studio, without flickering (Azure Data Studio) or inaccurate scrollbars (pgAdmin).
To achieve this, the results pane will wait for the execution to finish and request an individual data page as the user scrolls through the grid.
That means that the execution mechanism will not return any actual data, but only two things:
- Total count of results
- Result schema, or the metadata (column names and types).
And then the grid (or any other client) will request page data additionally.
To ensure smoothness of user scrolling in any environment, there are actually three different algorithms implemented (that can be set in a configuration or a command line when staring).
So now, I'll get a bit technical about this.
Execution algorithms
1) Server cursor execution
This method creates a unique PostgreSQL server cursor for each execution and lets the user scroll through it.
When execution is first requested, a new server cursor is created for that query:
declare [cursor_name] scroll cursor for [your query];
This will force PostgreSQL to create temporary data for your results on a server. The same mechanism will be used for temporary tables, so the only limit is your server storage space.
Then after that, a cursor will go to the end immediately :
move forward all in [cursor_name]
This will retrieve us a total number of results which is important for a smooth data grid to do its screen calculations.
And lastly, fetch zero items (empty) from the cursor:
fetch 0 in [cursor_name]
This will retrieve us a result schema metadata so we can draw a grid column headers properly.
This method will use most of the resources on the database server. It will use its temporary storage mechanism.
Also, it will send subsequent data pages over the network if the server is remote. That means that scrolling will not be as smooth because each data page needs to utilize the network.
But, it can be a good choice, depending on your configuration.
However, not all queries are suitable for server cursors. PGCODE will automatically detect is your query cursor suitable.
For example, queries that will do any data manipulation (even within the select query) or fetch cursor queries (can't do fetch on fetch).
So, if your query is not suitable for cursors, it will just fall back to the next method:
2) Local execution
Local execution will not create anything on the server (cursors or temp data), it will simply execute your query as is and start retrieving the data to the client.
Because we need to keep the data to allow smooth scrolling and we must be able to fetch data pages, without saving them to program memory (results can be quite huge) - retrieved data is saved to local an SQLite database optimized for ultra-fast inserts.
And because subsequent data page retrieval from that local SQLite file is very fast, this method gives the best results when scrolling through your data. And because it uses a local database, it doesn't take too much of your program memory.
However, there is a slight disadvantage: Execution cannot be completely finished until all of the data is fetched locally because we don't know the total count yet.
This is ok for small and even medium datasets but for large and extra-large - the user that initiated the query needs to wait, although execution itself is finished, data retrieval is in progress.
It is noticeable for example when I run a query with more than a million results. Waiting time is 15 to 20 seconds. Which is not a good user experience.
That's why there is a third method:
3) Mixed execution
The mixed execution method gave me the best results so far, that's why it is the default method for execution now.
What it does is actually, it creates a server cursors same as the first method, and then it goes up to fill the local SQLite database with the first 500 results and it returns the UI immediately.
This process is very fast, less than a second, so the data grid will receive information about the count and the metadata very fast and the user doesn't have to wait.
The rest of the result set (more than the initial 500) is retrieved into local SQLite in a background thread.
This method gives good results, even if the result set is hundreds of million records.
The only drawback is if the user scrolls down the grid too fast, it might not show the data immediately. But this can be mitigated with some sort of progress information on the UI, which I plan to implement next.
Final words
Progress on this project is satisfactory, and the execution part is, in my opinion, the most important and most challenging at the same time.
If anyone has a better idea of how to solve this more efficiently, I would certainly like to know.
However, because this is a side project, which I'm able to work on only on weekends and in the evenings, basically whenever I have some free time - it could be much faster.
If anyone is interested to help or contribute, the code is in this repository: github.com/vbilopav/pgcode
Also, any donation would help me greatly to take more time on this project. Here are the links:
- https://www.paypal.me/vbsoftware/5
- https://www.paypal.me/vbsoftware/10
- bitcoincash:qp93skpzyxtvw3l3lqqy7egwv8zrszn3wcfygeg0mv
And if any company would be interested in taking ownership or sponsorship, drop me an email: vbilopav@gmail.com
If someone is interested in an early build (exe file around 50MB), before I set up a website with a download section - contact me by email.